파이썬 판다스 데이터프레임 생성 - 비전공자도 이해하는 설명, python pandas DataFrame and pip list dict numpy array
판다스 데이터프레임 쉽게 생성하기
비전공자 입장에서 판다스 데이터프레임을 생성하는 것조차 이해가 잘 되지 않아요.
저 같은 경우엔 단순히 코딩만 따라치는게 전부였습니다.
저는 조금 쉽게 설명하고자 했어요.또한 최대한 알맹이만을 요약해서 전달하고자 합니다.
이것을 보시고 나면 적어도 정해진 포맷을 이해하고 이러한 범위 내에서 스스로 데이터프레임을 만들 수 있을 겁니다.
기초개념
우선 데이터프레임을 생성하기 전에 생각해야 할 것이 3가지가 있습니다.
- row index
- column index ( = column name )
- value
1. row index

row 인덱스는 가로줄로 나타난 row와 그들을 고유하게 지정할 index를 의미합니다.
0번은 철수이고, 1번은 영희, 2번은 맹구일때, 0, 1, 2 가 row index입니다.
row 인덱스는 주로 0으로부터 데이터 갯수까지로 나타냅니다. 각 숫자들은 중복이 없어야 합니다. (SQL의 PK를 의미한다고 보면 됩니다)
2. column index (=column name)

column 인덱스는 세로줄에 나타나는 속성들을 의미합니다.
'나이' '성별' '잔고' 등에 대한 다양한 사람들의 특징을 뽑을 수 있는 것들로 구분합니다.
3. value
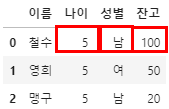
마지막으로 value는 row와 column이 만나는 지점에 생기는 값을 의미합니다.
0번의 나이, 성별, 잔고 같은 경우에는
0번은 철수이고 그는 5살, 남자, 잔고는 100원 이라는 식으로 만들 수 있습니다.
위의 3가지를 반드시 기억하고 데이터프레임을 만들어봅시다.
row인덱스는 별도의 인덱스 이름을 붙여주지 않습니다. 데이터프레임을 생성하면 row 인덱스는 자동으로 생성됩니다.
row 인덱스는 1씩 늘어나는 정수형으로 생성됩니다.
최대한 중복없는 많은 이름을 하기 위해선 정수형인 숫자 형태가 이상적이기 때문입니다.
주의할점은 0부터 시작된다는 점입니다. 1000개의 행이 있다면 0부터 999까지의 인덱스가 있음을 인지해야 합니다.
다음으로 컬럼들을 정의해봅시다.
컬럼을 정의한다는 것은 컬럼 인덱스의 이름들을 설정해준다는 것입니다. (ex.이름, 나이,성별, 잔고 등)
별도의 설정을 해주지 않는다면 컬럼 인덱스도 0으로부터 시작되는 숫자가 됩니다.
그러나 컬럼이름은 row인덱스와 다르게 이름을 꼭 붙여줘야 합니다.
그렇지 않으면 값이 무슨 의미를 갖는지 알기가 어렵습니다.

예를 들어 0번째 row 인덱스와 0번째 column 인덱스를 갖는 값 13이 있습니다. 이게 무슨 의미일까요? 이렇듯 column name을 설정해주지 않는다면 문제가 됩니다.
그러면 row index를 0이 아니라 의미있게 설정해주는것은 어떨까요?
아까 말했다시피 row index는 고유의 값으로 지정해야 되기 때문에 중복의 문제성이 있으면 안됩니다. 따라서 row는 중복되지 않도록 정수형으로 지정하고, column이름은 중복을 고려하지 않고 특징을 나타내는 이름으로 설정해주는게 좋습니다.
이제 파이썬 코드로 직접 작성해보죠.
파이썬 코드를 작성해서 데이터프레임을 만들 때에도 3가지 조건을 꼭 염두하고 만들어야 합니다.
row 인덱스는 정수형의 숫자로 생성이 된다고 하니 상관하지 않아도 됩니다. (1번째 조건)
column 이름을 설정해주어야 합니다.(2번째 조건)
생성할 데이터프레임의 컬럼 이름은 주로 리스트에 넣어줍니다. (순서 고려)
# 2번째 조건: 컬럼이름 만들기
new_column_name = ['나이', '성별', '잔고', '결혼여부', '출생지', '나이대']
데이터프레임 설정의 3가지 조건 중 2가지가 완료되었습니다.
남은 한가지는 value입니다.
value를 지정하는 방법은 크게 3가지로 전달할 수 있습니다.
- pip의 list
- pip의 dict
- numpy의 list
pip의 리스트를 적용한 데이터프레임
리스트 안의 리스트를 통해서 row에 삽입한다고 생각하고 리스트 객체를 생성해줍니다. (가로로 생성한다 생각)
생성한 객체(리스트)를 pd.DataFrame()이라는 판다스의 함수에 input값으로 넣어주면 데이터프레임의 형태로 리턴합니다.
여기서 pd.DataFrame() 안에는 옵션 파라미터를 설정할 수 있습니다. columns= 라는 값에 위에서 설정해주었던 리스트 객체를 지정해줍니다. (new_column_name)
결론적으로 데이터프레임 생성을 위해서는 아래와 같은 형태를 입력해야 합니다.
pd.DataFrame(데이터값, columns=컬럼이름리스트)
이 데이터프레임은 자동으로 각각의 row 별로 unique한 정수형의 row index를 만들어줍니다.
# list
# array_to_df.tolist()
list_to_df = list([['20', '남자', '2000', '미혼', '서울', '사회초년생'],
['50', '여자', '15000', '결혼', '서울', '은퇴예정자'],
['48', '남자', '20000', '결혼', '서울', '은퇴예정자'],
['32', '여자', '800', '미혼', '서울', '사회생활 1~10년차'],
['28', '남자', '1200', '결혼', '서울', '사회생활 1~10년차'],
['38', '여자', '3600', '결혼', '서울', '관리자 역할']])
# np.array(list_to_df)
pd.DataFrame(list_to_df, columns=new_column_name)
위와 같은 결과물은 다양한 방법으로 만들 수 있습니다.
pip dictionary를 적용한 데이터프레임
우선 dict형태는 key값과 value값이 있습니다.
데이터프레임을 만들때 dict를 넣어주면, key값은 column명이 되고, value값은 각각의 값이 됩니다.
여기서 value값들은 각 column에 대한 row들의 값이므로 리스트로 묶어서 적어줍니다.
# dict
dict_to_df = {'나이': [20, 50, 48, 32, 28, 38],
'성별': ['남자', '여자', '남자', '여자', '남자', '여자'],
'잔고': [2000, 15000, 20000, 800, 1200, 3600],
'결혼여부': ['미혼', '결혼', '결혼', '미혼', '결혼', '결혼'],
'출생지': ['서울', '서울', '서울', '서울', '서울', '서울'],
'나이대': ['사회초년생', '은퇴예정자', '은퇴예정자', '사회생활 1~10년차', '사회생활 1~10년차', '관리자 역할']}
pd.DataFrame(dict_to_df)pd.DataFrame({키1:[값1], 키2:[값2]})
value를 리스트로 적어도 되지만, row index마다 맞춰서 만들수도 있습니다. dict 안의 dict 구조로 적으면 됩니다.
첫번째 큰 dict의 키값은 column값이고, 그 안에 있는 dict의 키값은 row index값입니다.
# dict
dict_to_df = {'나이': {0: 20, 1: 50, 2: 48, 3: 32, 4: 28, 5: 38},
'성별': {0: '남자', 1: '여자', 2: '남자', 3: '여자', 4: '남자', 5: '여자'},
'잔고': {0: 2000, 1: 15000, 2: 20000, 3: 800, 4: 1200, 5: 3600},
'결혼여부': {0: '미혼', 1: '결혼', 2: '결혼', 3: '미혼', 4: '결혼', 5: '결혼'},
'출생지': {0: '서울', 1: '서울', 2: '서울', 3: '서울', 4: '서울', 5: '서울'},
'나이대': {0: '사회초년생',
1: '은퇴예정자',
2: '은퇴예정자',
3: '사회생활 1~10년차',
4: '사회생활 1~10년차',
5: '관리자 역할'}}
pd.DataFrame(dict_to_df)pd.DataFrame({키1:{인덱스0:값1, 인덱스1:값2}, 키2:{인덱스0:값3, 인덱스1:값4}})
데이터프레임 생성은 numpy의 ndarray 구조로도 가능합니다.
numpy의 ndarray와 pip의 list는 비슷한 형태입니다. 다만 장단점이 있는데요.
이에 대해서는 이전 블로그에 게시해두었으니 부담없이 보고 오셔도 좋습니다.
파이썬 판다스 데이터프레임 예제 반드시 알아야 하는 함수들, python pandas Series and DataFrame # 1
pandas Series DataFrame 함수의 기본적인 모든 것 파이썬 판다스에서는 기본적으로 알아야 하는 개념들이 있습니다. 특히 2차원의 데이터 조작을 하기 위해서 pandas의 기본적인 함수는 숙지하고 있어
koreadatascientist.tistory.com
ndarray는 키값이 따로 없기 때문에, pip list에서 만들었던 것처럼 columns= 라는 파라미터로 컬럼값을 지정해줘야 합니다.
그 외에는 pip list로 만든 데이터프레임과 생성방법이 동일합니다.
# ndarray
array_to_df = np.array([[20, '남자', 2000, '미혼', '서울', '사회초년생'],
[50, '여자', 15000, '결혼', '서울', '은퇴예정자'],
[48, '남자', 20000, '결혼', '서울', '은퇴예정자'],
[32, '여자', 800, '미혼', '서울', '사회생활 1~10년차'],
[28, '남자', 1200, '결혼', '서울', '사회생활 1~10년차'],
[38, '여자', 3600, '결혼', '서울', '관리자 역할']])
pd.DataFrame(array_to_df, columns=new_column_name)pd.DataFrame(ndarray형태, columns=컬럼이름리스트)
이번 시간은 집중적으로 #데이터프레임을생성 하는 방법에 대해서 다뤄봤습니다.
다음 시간에는 데이터프레임을 갖고 다시 list, dict, ndarray로 뽑아내는 방법을 알아보겠습니다.
추가로 데이터프레임에 관련된 핵심적인 함수들도 다뤄볼 것입니다.
이정도는 기본으로 알고 있어야 데이터분석하는데 요긴하게 적용할 수 있을 것입니다.