pandas Series DataFrame 함수의 기본적인 모든 것
파이썬 판다스에서는 기본적으로 알아야 하는 개념들이 있습니다.
특히 2차원의 데이터 조작을 하기 위해서 pandas의 기본적인 함수는 숙지하고 있어야 합니다.
하지만 필요한 함수를 설명해놓은 곳이 부족하고 공식문서는 영어로 되어있기에 이를 극복하고자 글을 남겼습니다.
매우 기초적인 내용이지만, 기본적이고 필수적인 내용입니다.
해당 방법에 대해서 친숙해지신다면 앞으로의 데이터분석 및 인공지능학습의 기본을 다지는데에 큰 기여를 할겁니다.
목차
- 개념
- 기본함수
- 데이터셋
- 샘플
- 저장하기 & 불러오기
- 타입
- 형태(nXn)
- 컬럼정보
- 연속형 개략적 분포
- 통계 요약
- 정렬
- Apply 함수
- 데이터프레임 생성 3가지(반대로도)
- ndarray
- list
- dict
- 컬럼 데이터 생성
- 컬럼 데이터 수정
- 데이터프레임 데이터 삭제
- 인덱스
- 데이터 선택
- 데이터 추출(필터; 불린 인덱싱)
- Null 처리
- Groupby & Aggregation
양에 압도되실 수 있습니다. 하지만 세부적인 내용보다는 과정을 이해하는데에 중점을 두었습니다.
또한 Long run 보다는 2갈래로 나눠서 운용하는것이 좋다고 판단하여, 1장과 2장으로 나눴습니다.
이번 pandas 설명은 기본적으로 파이썬의 list(리스트)와 dict(딕셔너리)에 대해서 이해를 했다는 가정하에 진행합니다.
또한 기본적으로 numpy의 array에 대한 개념도 이해한다고 전제하겠습니다.
간단히 설명하면 list, array는 서로 비슷한 구조이지만, list는 다양한 데이터 형태들을 넣을 수 있고(예를 들어 숫자와 문자열의 혼합) array는 그게 안된다는 겁니다. 하지만 array는 효율적이며 빠릅니다.
| list | array | |
| 장점 | 숫자와 문자 혼용(유연) | 요소들을 한번에 저장하여 빠르다(효율) |
| 단점 | 요소별로 따로 저장 반복문 사용이 불가피 |
다른 데이터 타입 혼용 불가 |
위에서 언급한 list, dictionary, array는 pandas의 Series와 DataFrame와의 호환으로 인하여 반드시 숙지해야 될 개념들입니다. 특히 numpy 라이브러리의 array 개념은 pandas의 근간이 되는 개념이기도 합니다.
시간이 된다면 이후에 자료형 구조의 개념에 대해서 정리를 해두겠습니다.
필요 라이브러리 호출
# 호출
import pandas as pd
데이터셋 생성
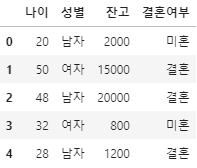
column_name = ['나이', '성별', '잔고', '결혼여부']
df_list = [[20, '남자', 2000, '미혼'],
[50, '여자', 15000, '결혼'],
[48, '남자', 20000, '결혼'],
[32, '여자', 800, '미혼'],
[28, '남자', 1200, '결혼'],
[38, '여자', 3600, '결혼']]
df = pd.DataFrame(df_list, columns=column_name)개인정보 DataSet을 pandas의 DataFrame 형태로 생성하는 코드이다.
참고로 DataFrame 생성은 위 방법 외에도 다양한 방법으로 할 수 있다.
해당 내용에 대해 궁금하다면 아래의 링크를 참고하시길...
파이썬 판다스 라이브러리에서 데이터프레임 생성하기, 판다스 공식문서 참조, pandas_cheat_sheet, p
파이썬 판다스 라이브러리에서 데이터프레임 생성하기, 판다스 공식문서 참조, pandas_cheat_sheet, pd.DataFrame() 안녕하세요 ! 오늘의 주제는 기본적으로 행과 열을 갖고 있는 형태를 만들어볼
koreadatascientist.tistory.com

위의 개인정보는 '나이', '성별', '잔고', '결혼여부'에 대한 내용이다. (위의 데이터는 가상의 데이터이다)
아래부터는 위와 같은 데이터프레임을 분해해보고 조작해보는 과정을 해볼것이다.
과정의 편의상 해당 데이터프레임은 df로 정의한다.
샘플(미리보기)
df.head() # 샘플, 기본값은 5개위의 데이터셋이 만약 100만명의 데이터셋이라면?
그 큰 규모의 데이터를 한번에 보기는 힘들것이다.
그러므로, 요약적으로 데이터셋이 잘 DataFrame안에 적재되어있는지, 어떻게 생겼는지를 보기 위해서는 일부의 샘플을 봐야 한다.
df.head() 라는 명령어는 위의 데이터프레임 중 가장 위의 5개의 행을 보여준다.
() 괄호 안에 숫자를 변경함으로써 보여지는 행 갯수를 바꿀 수 있다. (쓰지 않았을 경우 기본값은 5개)
반대로 가장 마지막 부분의 데이터를 보기 위해서는 df.tail()을 사용하면 된다.
df.tail() # 마지막 5행 출력
pd.set_option('display.max_rows', None) df로 할 때 행의 갯수 제한 없음참고로 pd.set_option()의 코드는 데이터 행 갯수를 조절하는 기능을 한다.
pandas의 설정을 바꾼다고 생각하면 쉽다. 위의 같은 코드는 행(row)을 모두 다 보여주는 것을 설정하는 의미이다.
참고로 이 옵션은 head()일 때 보여지는 기능이 아니라, df를 직접적으로 호출할 때를 의미한다.
데이터프레임 저장하기
df.to_csv('test.csv', index=False) # 데이터 저장하기해당 데이터프레임을 저장하고 싶으면 df.to_csv() 메소드를 사용하면 된다.
해당 데이터프레임은 to_OOO라고 명명하여 원하는 형태로 csv, excel 등으로 저장할 수 있다.
to_csv로 저장을 하면 경로는 현재 파이썬 코드 파일이 있는 경로로 저장된다.
참고로, 해당 경로를 정확히 모르겠다면 os 모듈을 호출하여 현재경로를 출력하는 함수를 입력하면 된다.
그 코드는 아래와 같으니 참조하도록 하자.
import os # 모듈 호출
os.getcwd() # 현재 경로 출력
데이터프레임 불러오기
df = pd.read_csv('test.csv') # 데이터 불러오기
df.head()excel 파일이나 csv 파일의 형태(그 외에도)는 파이썬 판다스에서 불러오는 기능이 있다. 바로 read_OOO 형태로 불러온다.
csv의 경우는 pd.read_csv("경로/파일명.csv", 그 외 옵션) 형태로 불러오고,
excel의 경우는 pd.read_excel("경로/파일명.xlsx", 그 외 옵션) 형태로 불러온다.
csv를 ,(콤마)로 나눠서 가져올건지 tab으로 나눠서 가져올건지, 혹은 excel 파일에서 특정 시트만 가져올 것인지 등등에 대해서도 조정할 수 있는 옵션이 있다.
보통 해당 옵션을 잘 몰라도 가져와서 데이터를 조작하기도 한다. 어느 방법이든 그런 기능이 있다는 것을 알아두면 나중에 찾아가면서 해결하기에 용이할것이다.
타입
df.info() # 타입
타입이라 썼지만, 엄밀히는 데이터프레임의 종합 정보라고 볼 수 있다.
특정 컬럼(예를 들어 이름, 나이 등)에 대한 이름과 null값의 갯수, 데이터 타입에 대한 정보를 보여준다. (심지어 데이터프레임의 용량까지 보여준다)
엄밀히 data type형태만 보고 싶다면 dtypes라는 함수를 사용하면 된다.
df.dtypes
데이터를 조작하기 전에 type에 대한 정보를 미리 아는 것은 상당히 중요하다.
이후에도 일처리를 두번하지 않기 위해서 미리미리 정보를 봐주는 습관을 들이자.
형태(nXn)
df.shape # 형태
데이터프레임이 몇 행(row) 몇 열(columns)인지 정확히 알고 싶을 때 쓴다.
왼쪽이 행을 의미하고, 오른쪽이 열을 의미한다.
해당 결과물은 튜플 형태로 반환이 된다.
연속형 통계 요약
df.describe() # 연속형 개략적 분포
데이터프레임 상에서 연속형(정수, 실수 등의 숫자형) 값을 갖는 컬럼에 대한 통계적 요약정보를 보여준다.
우리의 데이터프레임은 총 4개의 컬럼이 있음에도 불구하고 '성별', '결혼여부'는 숫자로 나타난 값이 아니기 때문에 해당 함수의 결과에서 제외가 되었다.
describe() 함수는 데이터프레임이 아닌 컬럼(연속형)에도 사용할 수 있다.
df['나이'].describe()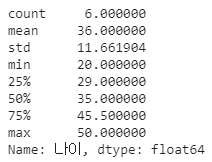
컬럼 값 분포
df['나이'].value_counts() # 컬럼 값 분포(기본값: 내림차순)
df['나이'].value_counts(ascneding=True) # 오름차순으로 변경가장 자주 쓰이는 함수 중 하나이다.
데이터프레임에도 사용 가능하나, 보통은 컬럼의 값별로 count하기 위해서 쓰인다.
기본적으로는 값의 갯수가 높은 순으로부터 낮은 순으로(내림차순)으로 되어있지만,
옵션 파라미터로 ascending=True로 설정해주면, 오름차순으로 볼 수 있다.

해당 오름차순의 결과를 보면 '값' 자체가 인덱스가 되어 있는것을 알 수 있다.
위의 결과에서 28, 38, 32, 20, 50, 48이라는 값이 pandas Series의 인덱스를 의미한다.
그런데 이 인덱스가 보여지는 순서대로 필요하다고 생각할 수 있다.
그럴 경우 아래와 같은 코드를 사용해보자.
df['나이'].value_counts().index # 시리즈 인덱스
그러면 해당 인덱스를 뽑아낼 수 있다.
해당 값은 tolist라는 함수를 사용하여 list의 객체로도 만들 수 있다.
df['나이'].value_counts().index.tolist()
만약 해당 인덱스를 하나의 컬럼 안의 값으로 만들고 싶다면 어떻게 해야될까?
이런 경우 아래와 같이 해보자
df['나이'].value_counts().reset_index()
value_counts()로 나타났던 시리즈라는 결과에서
인덱스 부분이 새로운 컬럼의 값이 된다. 해당 컬럼명은 보다시피 'index'이다.
그리고 새로운 인덱스가 0부터 순서대로 부여된다.
count를 하는 값의 순서들이 의미가 있을 경우 reset_index를 통해 인덱스를 컬럼화시킬 수 있다.
reset_index()를 통해서 현재 인덱스를 컬럼으로 추출하는 방법은 우리가 위에서 다뤘던 value_counts() 뿐만 아니라 결과가 Series형태(인덱스와 값)로 나오는 모든 경우에 대해서도 동일하다.
여기서 Series값은 인덱스와 값으로 나타나는 형태를 의미한다.
우리가 이전에 배웠던 describe()라는 통계 요약을 해주는 함수도 Series의 형태로 나오는데,
이에 대한 인덱스값이 필요할 경우에 reset_index를 통해서 해당 통계 지표를 새로운 컬럼으로 만들 수 있다.
df.describe().reset_index()
정렬
df['나이'].sort_values() # 특정 컬럼 정렬
df.sort_values(by=['나이', '잔고']) # 특정 컬럼 정렬2시리즈나 데이터프레임을 정렬된 상태로 보고 싶을 때는 sort_values라는 함수를 사용하면 된다.
시리즈.sort_values 혹은 데이터프레임.sort_values를 입력하면 된다.
하지만 기준을 정해줘야 한다. 즉, 어떤 컬럼을 기준으로 데이터프레임의 행들을 정렬시킬 것인지를 의미한다.
시리즈같은 경우는 특별히 설정해주지 않아도 해당 시리즈(column 값)안에서 정렬을 해줘도 되지만, 데이터프레임은 정렬의 기준을 잡아줘야 한다. 그것은 sort_values의 괄호 안에 by 값을 리스트 형태로 설정해주면 된다.
리스트 안에는 정렬하고자 하는 컬럼이름을 적으면 된다. → (by=['나이', '잔고'])
기본적으로 오름차순으로 설정되지만, 괄호 안에 ascending=False값을 넣어주면 내림차순으로 볼 수 있다.
sort_values함수의 결과물을 처리하는 방법은 2가지이다.
1. 다른 객체에 반환
2. 해당(연결된) 객체에 반환
df = df.sort_values(by='나이') # 결과물 반환방법1 (inplace=False가 되어있는 것)
df.sort_values(by='나이', inplace=True) # 결과물 반환방법2 (df 자체가 변경)[쉽게 설명]
inplace=True라고 하면 해당 데이터프레임이 정렬된 결과로 바뀐다.
inplace=False라고 하면 해당 데이터프레임이 정렬되지 않는다. 그 결과는 다시 객체에 반영해야 한다.
[자세히 설명]
inplace=True로 설정하면 해당 함수는 return이 None으로 된다.
반환하지 않고 해당 값을 그대로 바꿔버리기 때문에 위의 방법처럼 다른 객체에 할당하여도 none값만 나온다.
inplace를 설정하지 않은 경우(False) 해당 함수의 반환값은 데이터프레임으로 반환된다.
그러므로 다른 객체에 할당할 수 있는 것이다. (즉, return 값이 있다. 데이터프레임이 return된다.)
이 개념은 조금 어려울 수 있다. 하지만 inplace=True는 그 자체가 바뀌어서 반환이 없고, inplace=False(디폴트값)은 그 자체가 안바뀌고 반환이 있다. 라는 점을 알아둘 필요성은 있다.
그러나 어려우면 넘어가자. 언젠가 생각나는 때가 올 것.
| inplace | True | False |
| 결과 return값 | 없음(None) | 있음 |
| 설명 | 연결된 df 자체가 바뀜 | 연결된 df가 바뀌지 않고 새롭게 객체에 할당해줘야 한다. |
이제 본격적으로 데이터프레임을 조작해보도록 하자.
컬럼 데이터 생성
df['출생지'] = '한국' # 컬럼 데이터 생성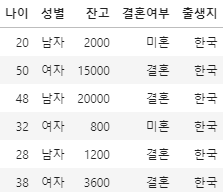
새로운 데이터컬럼을 생성하고 값을 대입하고자 한다면,
데이터프레임['컬럼명'] = 값 과 같은 형식으로 입력하면 된다.
보통 컬럼값을 입력하면 하나의 값이 입력되는것이 아니라, 해당 행 갯수에 맞춰서 값이 동일하게 전체입력된다.
컬럼 데이터 수정
df['출생지'] = '서울' # 컬럼 데이터 수정
생성된 컬럼값이 마음에 들지 않는다면, 컬럼값을 삭제해도 되지만, 그냥 덮어쓰기 하는 느낌으로 컬럼을 재생성 해주면 된다.
컬럼이름이 동일하다면 덮어쓰기와 같은 기능으로 데이터컬럼을 생성해준다.
앞에서의 내용은 매우 기초적인 내용이었지만, 이번부터 배우는 내용은 조금 까다로울 수 있다.
하지만 최대한 이해하려고 해보자. (사실 이 또한 데이터 전처리 계열에선 너무나 기초적인 내용이다.)
Apply 함수
# apply 적용할 함수 정의
def in_business_age_name(Age):
name = ''
if Age <= 25: name = '사회초년생'
elif Age <= 35: name = '사회생활 1~10년차'
elif Age <= 45: name = '관리자 역할'
else: name = '은퇴예정자'
return name해당 함수는 데이터프레임에서 특정 컬럼의 값을 내 입맛대로 바꿀 수 있는 기능을 한다.
즉, 내가 원하는대로 조건식을 만들어놓으면 해당 컬럼의 모든 값에 적용하여 바꿔준다.
바뀐 값들은 원래의 컬럼에 덮어쓰기도 되고, 새로운 컬럼을 생성하여 집어넣을 수 있다.
위의 함수는 파이썬 기초문법에서 배우는 '함수 정의' 부분의 내용이다.
해당 함수는 데이터프레임의 특정 컬럼의 값을 바꿔주는 기준이 되는 조건식이 된다.
위의 함수는 age를 넣으면 age가 어디 구간에 속하는지에 따라 string값으로 바꿔주는 기능을 한다.
파이썬에서는 단순히 함수명(인자) 형태로 함수를 호출하지만, pandas의 dataframe에서는 아래와 같이 사용한다.
df['나이대'] = df['나이'].apply(lambda x : in_business_age_name(x)) # Apply 함수

여기서 생소한 lambda라는 값은 일반적으로 함수 정의를 한줄로 표현하는 기능을 한다.
따라서 위의 함수를 해석하면 아래와 같다
나이 컬럼에 있는 x라는 값 모두를 in_business_age_name이라는 함수에 적용해서 return 시켜라.
'lambda x' 부분 에서 x값은 함수를 적용한 뒤 return 된 결과값이라고 이해하자.
컬럼.apply(lambda 결과값 : 함수이름(인자값))
1장은 대략적인 시리즈와 데이터프레임의 요약정보를 살펴보았다.
마지막 부분에는 컬럼값을 생성하고 수정하는 작업도 해보았으며,
함수를 만들어서 해당 조건에 맞도록 컬럼값을 바꿔주는 작업도 해보았다.
2장은 조금더 실질적으로 데이터 조작을 하는 방법을 배울 것이다.
그 또한 기초적이며 기본적인 내용을 다루지만 핵심적인 내용이므로 반드시 숙지하도록 하자.