캐글 커널 필사 중에 발견된 버그(아래의 커널을 필사한 과정에서 발생함)
https://www.kaggle.com/bertcarremans/data-preparation-exploration
Data Preparation & Exploration
Explore and run machine learning code with Kaggle Notebooks | Using data from Porto Seguro’s Safe Driver Prediction
www.kaggle.com
유한님 유튜브를 시청하며 공부하던 중에 자꾸 결과가 달라서 추적해봄.
https://www.youtube.com/watch?v=ysR7daBSEy8&list=PLC_wC_PMBL5NLKkMooi-n4iK4gv3VqXyo&index=2
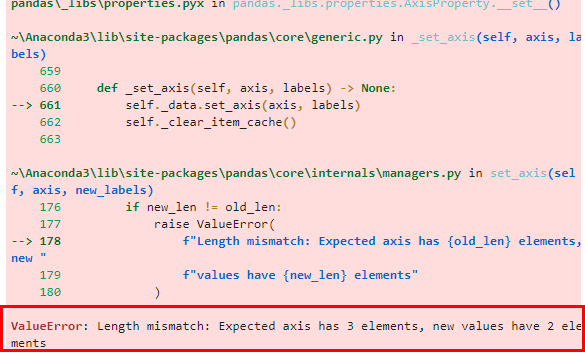
결론적으로 뭐가 문제냐면
리스트에 값을 추가하는 반복문에 조건문이 있었음.
근데, 조건문에 해당 컬럼의 dtype가 int가 맞는데도 불구하고 자꾸 False가 뜨니까
데이터프레임을 만들어도 뭔가 결과창이 안맞아!!
그래서 문제인 부분을 끝끝내 찾았습니다.

그래서 해당 컬럼이 int인지 불린식을 적용해보았더니 False가 뜨는 것이 아닌가...?

저 컬럼은 분명히 int64라고 찍혀있습니다만...? (int64로 해버리면 변수로 인식되서 에러뜸)
웃긴건 float64는 어떻게 쓰든간에 True로 나옵니다만...?
그래서 캐글코리아 카톡에 질문을 해봤더니 여러분들이 고민을 해주심

웃긴건 isinstance에서 int 대신 object로 불린을 하면 True로 나옴!!

더 웃긴건 .dtype로 object를 해보면 False로 나옴ㅋㅋㅋㅋ

어떤 분의 의견으로 np.int64로 해보니 dtype는 되고, isinstance는 또 안된다.

여튼 여기서 시간을 얼마나 쓴지 모르겠지만,,,,
버그인것으로 잠정적 결론?

어휴 이미 스터디 끝난듯한 피로감...
판다스여 영원하라 ~ 버그없이 ~