파이썬 판다스 데이터프레임 합치기, pd.concat(), 열 합치기, 행 합치기, python pandas library cheet sheet

데이터 프레임을 생성했는데 행으로 합치는 법과 열로 합치는 법을 살펴보겠습니다.
우선 데이터프레임을 하나 만들어보죠.
column = ['이름', '나이', '사는곳']
# df1 데이터프레임 생성
df1 = pd.DataFrame([
['김길동', 18, '서울'],
['안홍조', 28, '경기'],
['강국지', 30, '부산']
], columns=column)
# df2 데이터프레임 생성
df2 = pd.DataFrame([
['홍연', 21, '강원'],
['이박사', 44, '경기'],
['공석사', 34, '충북']
], columns=column)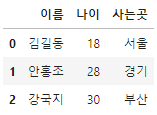
이 데이터프레임들을 하나의 데이터프레임으로 합쳐보겠습니다.
위아래로 붙여야 말이 되겠죠? 양옆으로 붙이면 이상한 데이터프레임이 되겠죠?
df3 = pd.concat([df1, df2])
df3.head()

그러나 무언가 이상합니다. 발견했나요?
행 인덱스가 중복되지요.
이렇게 되면 나중에 참조할때 상당한 문제가 생깁니다.
2가지 방법이 있습니다.
가장 간단한 방법은 pd.concat()의 파라미터로 ignore_index = True를 설정해주는 겁니다.
df3 = pd.concat([df1, df2], ignore_index=True)
df3.head()
다른 방법으로는 인덱스를 리셋해줘야 합니다.
df3.reset_index()
reset_index()의 특성상 기존의 인덱스는 feature로 생성되고 새로운 인덱스가 sort되서 할당이 됩니다.
그러나 이대로 두면 기존 데이터프레임에 적용되지 않습니다.
inplace = True 파라미터를 반환하거나, 새롭게 df3에 할당시켜줘야 합니다.
df3 = df3.reset_index()
# df3 = df3.reset_index().copy() 를 권장합니다.
# 혹은 df3.reset_index(inplace=True)
# df3.drop('index', axis=1, inplace=True)
# 인덱스를 또 드랍하는것이 번거로우니,
df3.reset_index(drop=True)
#를 추천드립니다.
간단한 방법과, 조금 복잡한 방법으로 나눠서 인덱스 설정을 살펴봤습니다.
결국 우리가 원하던대로 기존의 열에 새로운 행 데이터셋을 합치는 결과물이 완성되었습니다.
자 그러면, 반대의 경우도 생각해봐야겠죠? 동일한 열에서의 추가를 봤으니 그 다음은?
고정된 행에서, 오른쪽으로 붙여나가는 열의 데이터(피처 데이터)를 추가하는 겁니다.
기존의 데이터셋 df1을 다시 생성해보죠.
df1 = pd.DataFrame([
['김길동', 18, '서울'],
['안홍조', 28, '경기'],
['강국지', 30, '부산']
])자 이제 3명의 가상인물의 추가적인 정보를 만든 데이터프레임과 합쳐보겠습니다.
이는 df2로 생성합니다.
df2_column = ['직업', '종교', '특이사항']
df2 = pd.DataFrame([
['의적', '불교', '홍길동아님'],
['피부과의사', '천주교', '얼굴홍조없음'],
['요리사', '기독교', '']
], columns=df2_column)
자 이제 df1과 df2를 합쳐보겠습니다. axis=0(행)이 아닌, axis=1(열)끼리 붙여야겠죠?
df3 = pd.concat([df1, df2], axis=1)
오늘의 코드는 여기까지입니다.
위의 개인정보는 임의로 정한 가상의 인물이며 특정인을 지칭하지 않는다는 점 알립니다.
감사합니다.
'파이썬 & 인공지능 > pandas library' 카테고리의 다른 글
| 파이썬 판다스 컬럼 이름 변경하기, df.columns=[], rename(columns={}), rename 함수 (0) | 2020.04.14 |
|---|---|
| 파이썬 판다스 데이터프레임 정렬 방법 sort_values() (0) | 2020.04.13 |
| 파이썬 판다스 melt() 사용법, pd.melt() (0) | 2020.04.06 |
| 파이썬 판다스 라이브러리를 활용해서 데이터프레임 생성, 멀티인덱스 생성, pd.MultiIndex.from_tuples() (0) | 2020.04.06 |
| 파이썬 판다스 라이브러리에서 데이터프레임 생성하기, 판다스 공식문서 참조, pandas_cheat_sheet, pd.DataFrame() (0) | 2020.04.06 |
