가끔가다 데이터프레임에서 컬럼 이름을 변경해야 하는 경우가 있습니다.
여기서는 크게 두가지의 경우를 살펴볼 것입니다.
feature(열)의 크기가 작다면 둘 중 어느방법을 사용해도 상관 없습니다
다만, 특정 컬럼만 매칭해서 바꾸고 싶은 경우에는 rename()메소드로 컬럼 인자를 반환해줘야 합니다.
설명보다는 예시로 들어가봅시다.
데이터프레임을 생성합니다.
df = pd.DataFrame({
'a': [4, 5, 6],
'b': [7, 8, 9],
'c': [10, 11, 12]},
index = [1, 2, 3]
)
컬럼명들을 'A', 'B', 'C'로 바꾸고 싶다고 가정하면,
크게 두가지 방법이 있습니다.
1. df.columns = [] 리스트 형태로 반환하거나,
2, df.rename(columns={}) 딕트 형태로 반환하는 방법입니다.
차이점이 있습니다.
리스트 형태는 반드시 모든 피처들을 입력해줘야 됩니다.
즉, 열의 피처 개수만큼 리스트 인자가 들어가 있어야 된다는 거죠.
하나라도 부족하면 에러가 뜨게 됩니다.
df.columns = ['A', 'B', 'C']
성공적으로 바뀌었습니다.
바뀌기 전의 데이터프레임에서
df.columns의 리스트 인자를 피처 개수 3개보다 적게 입력해주면 어떻게 될까요?
새롭게 데이터 프레임을 초기화 합니다.
df = pd.DataFrame({
'a': [4, 5, 6],
'b': [7, 8, 9],
'c': [10, 11, 12]},
index = [1, 2, 3]
)리스트 인자를 기존 피처개수 3개보다 적은 2개로 입력해보겠습니다.
df.columns = ['A', 'B']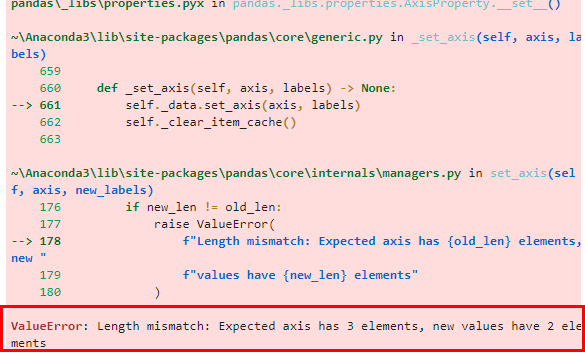
에러를 보시면. "열은 3개인데, 너는 2개만 값을 입력했다" 라는 에러메시지가 뜹니다.
즉 df.columns = [] 방식으로는 반드시 컬럼의 개수를 맞춰줘야 됩니다.
그러면 두번째 방법을 살펴보죠.
df.rename(columns={})
rename의 파라미터인 columns를 딕트 형태로 반환하는 겁니다.
여기서 키 값은 기존의 컬럼이름이고, 밸류 값은 새롭게 지정하고 싶은 이름입니다.
다행히도 이 방법은 반드시 3개의 인자를 모두 반환할 필요가 없습니다.
키 값을 지정해준 부분만 바꿔주기 때문입니다.
(기존 df에 적용시키기 위해 inplace=True 인자를 넣어줍시다.)
df.rename(columns = {'A':'에이', 'B':'비', 'C':'씨'}, inplace=True)
모든 컬럼의 이름이 바뀌었네요.
그러면 'C' 컬럼은 바꾸지 않도록 하기 위해서 왼쪽부터 두 열만 바꿔봅시다.
df.rename(columns = {'A':'에이', 'B':'비'}, inplace=True)
아까 리스트 형태로는 반드시 모든 컬럼의 갯수만큼 반환해야 했는데,
딕트 형태로 파라미터를 반환하는 rename() 함수는 필요한 피처의 이름만 바꿀 수 있어서 좋네요.
요약
컬럼 네임을 바꾸는 방법이 두가지가 있다.
1. df.columns = [] 형태로 리스트를 반환하는 방법
이것은 반드시 리스트의 len()과, df의 열의 길이가 동일해야 한다는 점.
2. df.rename(columns={}) 형태로 딕트를 반환하는 방법
이것은 모든 열을 다루지 않고, 필요한 열만 키 값으로 지정해서 바꿔줄 수 있다.
'파이썬 & 인공지능 > pandas library' 카테고리의 다른 글
| 파이썬 판다스 데이터프레임 합치기 3가지 - 비전공자의 친절한 설명 in python pandas merge (0) | 2020.11.18 |
|---|---|
| python pandas bug! int boolean bug! 판다스 버그 발견! (0) | 2020.04.14 |
| 파이썬 판다스 데이터프레임 정렬 방법 sort_values() (0) | 2020.04.13 |
| 파이썬 판다스 데이터프레임 합치기, pd.concat(), 열 합치기, 행 합치기, python pandas library cheet sheet (0) | 2020.04.09 |
| 파이썬 판다스 melt() 사용법, pd.melt() (0) | 2020.04.06 |




