평균과 분산을 억지로 외우며 듣는 여러분들께 바칩니다
(저같은 통계수업 듣는 비전공자들 화이팅...)
평균과 분산에 대한 개념을 정말 쉽게 뿌셔보겠심당!!
우리는 이전시간에 어떠한 자료들을 대표적으로 나타내는 방법인 대표값에 대해서 배웠다
혹시라도 안보고 왔다면, 이번파트를 위한 필수적인 내용들이 있으니 마지막 부분의 요약이라도 보고오길 바란다!!
koreadatascientist.tistory.com/66
평균과 분산은 무엇일까? 비전공자들을 위한 통계 기초
비전공자도 쉽게 이해하는 대표값의 개념과 산포도의 개념 뿌시기!! 대표값을 배우기 전에 이전의 내용에 대해서 충분히 숙지했는지 확인해보고 올 것!! 통계학 배우려면 자료형과 척도는 알아�
koreadatascientist.tistory.com
자 여기서 우리가 가장 마지막에 문제제기 한 내용을 기억하는가?
그렇다. 평균이라는 대표값 하나만으로는 해당 자료(데이터)들을 표현하기에는 역부족이란 것이다.
뜨끈한 예시
평균 점수 50점인 학생 두명의 그룹과외를 맡을 때,
평균만 보고 ok를 했다 한들,
각각의 점수가 0점과 100점이라면
골때리는 상황이 발생하기 때문....(누구에게 맞춰서 가르쳐야돼?!)
(실제 통계를 활용한 경우는 이러한 과외점수 수준의 문제들이 아니다)
오우쉣,, 그럼 저거에 대한 해결책은?!
이것에 대한 대안으로 '산포도' 의 개념이 있다. (산포도 사진이 기억나는가?)
산포도는 흩어진 정도를 의미한다. 산포도 값이 클수록 흩어진 정도가 크다.
반대로 산포도 값이 작을수록 흩어진 정도가 작을 것이다. 보통 후자(작아지는 것)를 목표로 한다.
참고로 산포도는 음의 수가 나타나지 않는다(나중에 식을 보면 이해가 될 것)
대표값에는 6가지가 있듯이 산포도도 여러가지가 있다.
우선 가장 대표적인 산포도인 분산에 대해서 배워보자.
분산
 표본분산의 공식
표본분산의 공식
분산의 식 형태는 이러하다. 엄밀히 이 식은 '표본'분산이다.
맨 앞단에서 기술통계학과 추론통계학이 기억나는가?
5000만명이라는 전체 집단에 대한 요약을 나타내는 통계학이 기술통계학이고
5000명을 가지고 나머지 4999만 5000명을 추론해나가는것이 추론통계학이다.
조금 더 부연설명이 필요하면 아래 링크에서 확인해보자!!
기술통계학과 추론통계학에 대한 아주 친절한 설명(feat.비전공자를 위함)
기술통계학 기술통계학은 모집단으로부터 표본을 추출하고 나서 표본이 가지고 있는 정보를 쉽게 파악할 수 있도록 데이터를 정리하거나 요약(숫자 또는 그래프)하는 절차를 다루는 분야이다.
koreadatascientist.tistory.com
실제 세상에선 5000만명을 모두 전수조사 할 수는 없다.
대신에 5000명으로 나머지를 추론해야 한다.
이러한 과정에서 5000명을 '표본'이라고 칭하고,
해당 표본의 평균과 분산을 통해서 모집단의 평균과 분산을 추론해나가는 것이다.
지금당장 이해가 된다고 하지 않아도 문제없다.
핵심은 5000명은 표본이란 것이고, 결국 이 표본을 갖고 모집단(5000만명)을 유추해내야 한다는 것 !
이전까지는 주로 설명 위주였다면
이번에는 분산의 식에 대해서 논해야 할 필요성이 있다.
앞에서 배웠던 조화평균 기하평균과 같은 조금 더 복잡한 식은 탐구하자고 안하겠다.
대신 산포도의 대표적인 영역인 '분산'에 대한 식은 숙지해두고 있으면 앞으로의 통계 인생이 편할 것이다.
절대 쫄지 말 것. 한땀한땀 뜯어서 분해시켜보면 아무것도 아니다
표본분산의 공식
자, 위의 식에서 의문을 가질수 있는 (그러나 몰랐을 때는 의문이랄게 있나 싶었던)
3가지에 대해 탐구해보자
참고로 각 통계적 기호에 대해서 초급자들은 상당히 힘들 수 있으므로, 나중에 따로 정리해둔 자료를 올릴 것이다.
그러니 여기서는 간단히만 설명하겠다.
S^2: 분산
n: 표본
x: 자기자신의 값(예: 키173, 키176, 키178, 키181 등등)
x바: 평균(예: 키의 평균 174.7)
∑(시그마): 모두 더하라
 표본분산의 식
표본분산의 식
3가지에 대한 의문점
- 왜 n이 아니라 n-1일까? (여기서 n은 표본의 수 이다 → 왜 5000명이 아니라 4999명일까?)
- 왜 평균을 뺄까? (가장 오른쪽에 있는 x바 형태는 평균을 의미)
- 왜 제곱을 할까? (가장 오른쪽에 자기자신인 x와 x바의 차이를 제곱한 의미)
우선 2번 3번을 먼저 논해보자.
가장 오른쪽 식에서 제곱부분만 제외한 식을 한번 생각해보자.
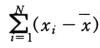 표본분산의 식 중 오른쪽 부분
표본분산의 식 중 오른쪽 부분
그러면 식 형태가
자기자신(x)에서 평균(x바)을 뺀것들을 모두 더하게 되는 식이 된다.
예를 들면, 키(x)가 170, 173, 176 이라고 할 때, 평균키(x바)가 173 이라면,
(170 - 173) + (173 - 173) + (176 - 173) 과 같은 형태로 되는 것이다.
충격적인 사실
그러나 어떤 데이터나 자료를 가져와도
자기자신에서 평균을 뺀 것들의 총합은 무조건 '0'이 된다.
띠용?!
위의 경우, 예시를 볼까?
-3 + 0 + 3 = 0
이것만 그럴 것 같나?
다른 예시 무한히 가져와봐라 무조건 0이다.
그래서?
이런것들은 수학적으로, 통계적으로 의미가 없다.
다 더해서 0이 된다는게 무슨 의미가 있는데..?
그렇다면, 0이 안되도록 절댓값을 씌운다면?
|-3| + |0| + |3| = 6
(참고로 절댓값은 마이너스를 플러스로 바꾸는게 아니라 내부가 마이너스인 경우 마이너스를 붙여 나오는 것이다.)
오 다 더해도 0이 안되네?!
재밌는 사실은, 이러한 공식이 실제로 있다는 것이다!

평균절대편차
평균절대편차(mean absolute deviation)라고 한다.
좋은 산포도 중 하나이다.
생김새도 잘 보면 분산과 흡사하다.
 분산
평균절대편차
분산
평균절대편차
n-1 대신 n을 쓴 것 뿐이고, 제곱 대신 절댓값을 쓴 것 뿐이다.
그런데 왜 산포도로써 표본분산은 절대값인 이 식을 채택하지 않았을까?
답은 '평균'이라는 대표값은 '제곱'과 궁합이 잘 맞기 때문이다.
?? 그게 또 뭔소리여
표본분산
위에서 S^2는 표본분산의 식이다.
오른쪽 부분의 식을 보자.
x바 대신에 a라는 미지수를 넣어보자.
 너무 형편없게 편집했다;
너무 형편없게 편집했다;
그렇게 하면 (x - a)^2 이 될텐데, 이것은 2차방정식의 형태로 나타낼 수 있을 것이다.
자, 아까 산포도는 흩어진 정도를 나타내는 것이고 이는 최소가 되는것을 지향한다고 했지?
그렇다. 이 이차방정식도 최소가 되는 것을 지향하도록 설계해야되는데 (왜? 산포도는 최소가 되어야 하니까)
여기서 2차방정식의 최솟값 개념이 나오는 것이다.
잊지 말 것 - 이 그래프에서 y값은 분산을 의미하며 이는 최소가 되어야 한다!!
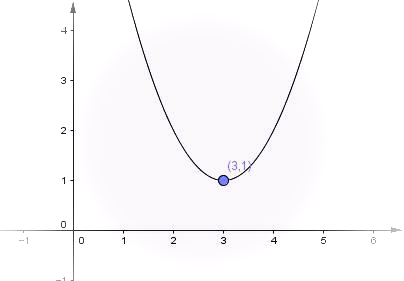 x=3에서 y는 최소값이며 그 값은 1이다
x=3에서 y는 최소값이며 그 값은 1이다
x가 3일 때에 최소값(분산이 최소가 되는 지점)이 1이 되도록 설계 하는 것이다.
만약 x가 3보다 크거나 작은 경우에는 어쨋든 y는 1보다 크기 때문에
분산이 최소가 된다고 할 수 없다.
기억해라. 이 그래프에서 y는 산포도(분산)의 값이며 이는 최소가 되어야 한다! (누차 반복해도 모자람)
y = (x-a)^2 + 1
위의 식을 정의할 수 있는가?
y = (x-3)^2 + 1 이다.
만약 최소값이 0이 되는 경우가 되려면 식이 어떠한 형태로 나와야 될까?
y = (x-3)^2 + 0 으로 나오면 되지 않을까?
👏👏👏👏👏👏👏👏👏👏
그렇다
우리가 지금까지 분산식에서 말하고자 했던 것이 이것이었다!!
 분산식에서 오른쪽 부분
분산식에서 오른쪽 부분
y = (xi - a)^2에서 2차방정식이 최소가 되는 a값은 x바가 된다. ( 마지막에 +0이 붙은게 보이는가? )
결국 이러한 이유에서 평균을 빼버리는 제곱의 형태로 나타난다고 이해하면 된다.
절댓값의 형태인 평균절대편차의 경우는 그럼 어따가 쓰니?
 평균절대편차
평균절대편차
여기서의 절댓값 안의 수를 최소로 만드는 x바 값은 무엇이 될까?

바로 중위수이다. 5000만명을 자산 순서대로 한 줄로 세워서 정확히 2500만명째인 사람의 위치!! 딱 중간!!
어떤 것은 산포가 최소가 되는 대표값이 평균이고(분산), 어떤 것은 중위수(평균절대편차)이고 신기하지 않은가?
나만신기한가..
자, 마지막으로
3가지 의문점 중 첫번째인
표본분산에서 n이 아닌 n-1인 이유에 대해 알아보자.
결론적으로 한 줄로 설명할 수 있다.
"표본분산이 모분산의 불편(不偏)추정량(비편향추정량)이 되도록 하기 위해서"이다.
뭔소리야?
여기서 "불편"은 "심기가 불편하다" 가 아니라
편향되지 않은(편애하지 않다를 생각하면 쉽다)이라는 개념이다.
단계별로 생각해보자.
우선 우리가 표본을 뽑아서 추정할 때에는 '표본'은 모집단을 추정하는 일부일 뿐이다.
그렇기 때문에 표본분산과 모분산이 같을 리가 없다!!
(당연한소리, 5000명을 뽑아서 조사한 것이 실제 5000만명의 결과와 같을리는 없지않은가)
그렇지만 표본 분산은 모분산으로 향해 간다.
표본이 많아질수록 모분산에 가까워지겠지?
여기서 모분산을 향해 가는 핵심이 n-1이다.
그래서 어쩌라는거지... n-1이 뭐냐고...
n-1은 #자유도 (degree of freedom)라고 한다.
N개의 값이 주어졌을 때의 자유도란 서로 영향을 받지 않고 독립적으로 결정되어질 수 있는 값의 개수를 뜻한다.
무적권 이해할 수 밖에 없는 예시
n=3이고 X1, X2, X3라는 임의의 값이 있다.
X에 대한 평균을 구하고자 한다.
그러면 평균은 1/3 * (X1+X2+X3) 가 되겠지?
자 여기서, 우리가 X에 대한 평균을 100이라고 가정하자.
그리고 다른 값들을 하나씩 우리가 선택해보자.
우리맘대로 X1은 50, X2는 150이라고 정해보자. 이제 X3을 정해야겠지?
근데 문제가 생겼네?
X3도 내가 마음대로 정할 수 있나?
없다
즉 여기서 X3는 다른 값에 의해 영향을 받고, 독립적으로 결정될 수 없는 값이 된다.
앞에서 본 자유도의 개념을 기억하는가?
영향을 받지 아니하고, 독립적으로 결정될 수 있는 값의 개수는 몇개인가?
방금 예에서는 설명했듯이 X1,X2로써 총 2개이다. 이게 자유도의 개념이다.
즉, 3개 중 2개가 자유롭게 결정할 수 있다는 것이다. 나머지 하나는 2개가 어떻게 되는지에 따라 바뀌니까.
마지막으로 분산과 표준편차의 관계에 대해 살펴보자
 표본분산 식
표본분산 식
분산은 어찌됐건 제곱들의 평균이지?
자기자신들(x)에서 평균(x바)를 뺀것들의 제곱합 형태니까!
이 제곱들의 평균(1/n-1)은 결국 기존에 우리가 궁금해했던 자료들에 비해 값이 너무 펌핑 되어서 결과가 보일 수 있다.
펌핑? 뭔소리야
키의 흩어짐(분산)을 비교하려면 평균 앞뒤로 +- 10cm 안에서 놀아야 되는데, (예를 들면 어떤 집단의 평균키가 170인데 나머지 사람들의 분포가 160~180이더라. 정도가 납득이 되잖아)
그런데 분산은 제곱들의 평균을 보여주니까 값이 10이 아닌 100이 되어버려서 해석하기에 까다롭다는 의미이다. (평균이 170인데 분산으로 표현하면 "키의 분포가 +-100cm?" → 납득이 안되고 직관적으로 이해하기도 힘든 수치이다.)
그래서 우리는 이 분산에 루트를 씌어준다.
그러면 우리가 해석하기 용이한 10(루트100)이라는 값이 나오게 되는 것이다.
우리가 분산을 구한것은 결국 산포도를 나타내기 위함이지만,
해석의 용이성을 위해서 해당 분산 값을 루트를 씌어서 표준편차로 바꿔주는 과정이 필요하다.
분산은 계산을 위하여, 표준편차는 해석을 위하여 존재하는 것이라 이해하면 편할 것이다
조금은 쓸데 없을 수 있는 질문
그러면 애초에 분산에서 불필요하게 제곱을 하지 않고 바로 표준편차를 구하면 되잖아?!
아주 좋은 질문 !!
이미 우리가 앞에서 다룬 전제를 무시하는 질문이다.
자기자신(x)에서 평균(x바)를 뺀 것을 모두 더하면, 0이 된다. (-3 + 0 + 3 = 0 기억나는가?)
허허,, 이러한 이유로 눈물을 머금고 펌핑(제곱) 시킨 뒤에 원하는 값을 구한 후
다시 축소(루트)시키는 것이다. 그로써 표준편차가 탄생한 것이다.
핵심 요약
- 문제제기: 대표값인 평균으로는 데이터를 보여주기에 역부족
- 해결책: 분산(산포도 중 대표적인 한가지 방법)
- 분산의 식에 대한 의문점 3가지
- 분산에서 제곱 부분에 대한 의미
- 분산에서 표본의수-1 (n-1)이 의미하는 것
- 분산과 표준편차는 어떤 관계인가
해당 내용에 대해서 한줄이라도 설명이 가능하다거나, 아까 배웠던 내용이 스쳤다면 오늘 학습은 성공이다.